“Compiler”的版本间差异
跳到导航
跳到搜索
小 |
小 |
||
| (未显示同一用户的1个中间版本) | |||
| 第1行: | 第1行: | ||
{{Template:In_Progress}} | |||
所以你想从头开始制作自己的 [[compiler|编译器]]? | |||
这并不容易。 有些编译器的复杂度与整个简单操作系统相当。 | |||
尽管如此,它还是一个有趣且/或有教育意义的项目。 以下是开始之前你应该知道的一些事情: | |||
== 利弊 == | |||
为什么要编写编译器而不是使用现有的编译器? | |||
优点: | |||
* 你想要的语言和目标的编译器可能根本不存在。 | |||
* 教育目的,你可以更好地了解 [[How kernel, compiler, and C library work together|内核、编译器和运行时库如何一起工作]],以及实现一种语言需要什么。 | |||
* 说到这里,你可以立即实现自己的新编程语言!有多酷啊? | |||
* 你可以对正在编译的程序执行几乎任何操作: | |||
** 以你喜欢的格式添加调试数据 | |||
** 添加分析辅助工具 | |||
** 重新编写和重新排列程序的各个部分 | |||
** 针对特定事物进行优化 | |||
** 将其扔掉并替换为其他程序 | |||
* 编译的程序将针对你的机器或你正在开发的操作系统定制。 | |||
缺点: | |||
* 需要完全理解所需的语言。要始终制定充分的官方语言规范。 | |||
* 还需要了解特定于目标的汇编过程。 | |||
* 关于 [[Getting Started|起步指南]]这篇文章的大多数注解也适用于编译器。 | |||
* 完全实现一套语言规范将很棘手。 | |||
* 如果你想在编译代码的大小/速度优化方面与GCC竞争,则必须非常非常擅长做编译器。 | |||
== 术语 == | |||
好吧,如果你还打算要做,现在让我们看看编译器是如何工作的: | |||
[[Image:compilers1.png]] | |||
术语: | |||
* “Host主机” 是编译器本身运行的环境。 | |||
* “Target目标” 是要运行编译后得到程序的地方。 | |||
* “run-time运行时” 是目标上存在的资源 (库,进程等)集合。 两台具有相同硬件的机器在运行时资源的可用性方面不同,有时则被认为是不同的目标,因此一个程序可能在一个计算机上运行,但不能在另一个计算机上运行。 | |||
* “[[Executable Formats|可执行文件-executable]]” 是一种文件,其中包含目标启动程序所需的信息。 它通常是直接的二进制文件,但通常结构更精细,例如包含链接和重新定位信息。 | |||
* “link链接” 表示程序知道如何与运行时对接,并依赖运行时的某些功能。 它是由 [[Linkers|链接器]] 创建的,并且在自主(free-standing)程序 (即OS内核) 中不存在。 | |||
如果主机和目标是相同的,则产品是 “原生可执行文件(native executable)”。 99%的情况下,你遇到的就是这种。 | |||
如果编译器能够为与主机不同的目标生成可执行文件,则它就属于 “交叉编译器(cross-compiler)”。 | |||
如果编译器能够编译出自己,那就是 “自我托管(self-hosting)”的。 | |||
== | == 内部 == | ||
[[ | [[Image:compilers2.png|right]] | ||
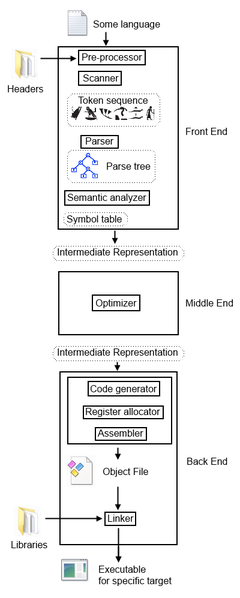
编译器也有奇特的内部结构。 你不必完全能复述这里描述的那些定义,但目前这是一个很好的路线图。 通常,编译程序的任务分为几个单独的任务: | |||
* ''' Front End 前端 ''' 采用某些特定语言的源代码,并输出通用的 “中间表示” (IR)。 | |||
* '''Middle End 中端 ''' (可选) 采用中间表示形式,以某种方式对其进行更改,然后将其输出回去。 | |||
* '''Back End 后端''' 获取IR并输出特定目标的可执行文件。 | |||
这种划分的想法是,通过具有不同前端和不同后端的集合,你可以将任何语言的程序编译到任何目标,因为IR对于所有目标都是相同的。 | |||
=== 前端 === | |||
==== | |||
* 首先,前端通常包括某种用户接口,以便可以接受文件和编译选项。 然后,有几个阶段的处理。 | |||
* 对于类似C的语言,会有一个 ''' pre-processor 预处理器 ''' 从头文件中复制并粘贴代码,删除注释执行宏扩展并执行其他相对简单的任务。 | |||
* 然后,一个 '''scanner 扫描器''' (或 '''tokenizer 分词器''') 将源文件分解为一系列分词(Token),代表一种语言的基本单词 (即标识符,数字和字符串常量,诸如 “if” 和 “when” 的关键字,标点符号和分号) | |||
* 然后,'''parser解析器''' 读取令牌流并构造 '''parse tree解析树''',这是一种树状结构,表示源代码的结构。 就语言制作而言,每个源代码文件都是该语言的 “sentence 句子”,并且每个句子 (如果有效) 都遵循特定的语法。 | |||
* 接下来,'''semantic analyzer 语义分析器''' 遍历解析树,并确定该 “句子” 每个部分的特定含义。 例如,如果是声明语句,则它将条目添加到符号表中,并且如果它是涉及变量的表达式,则它将符号表中已知变量的地址替换为表达式中的变量。 | |||
* 最后,前端生成一个 '''Intermediate Representation 中间层表达''',它捕获程序源代码特定的所有信息。 一个好的IR可以说明源代码所表达的所有内容甚至更多,还可以捕获该语言对程序的其他要求。 它可以是 '''parse tree 解析树 ''' 、 '''abstract syntax tree 抽象语法树 ''' 、 '''three address code 三地址代码 ''' 或更奇特的东西。 | |||
值得注意的是,这种划分纯粹是为了方便编译器开发人员。 大多数类型的 '''parsers 解析器''' 可以轻松读取字符流,而不是分词令牌流,因此不需要单独的扫描器。 一些非常强大的解析器类甚至可以 “在阅读完成之前” 确定语句的语义含义,因此不需要语义分析器。 不过,它们可能会更难理解和使用。 | |||
=== | === 中端 === | ||
这里会使用一大堆旨在尝试使程序更高效的算法。 我对这部分不是很熟悉,所以我就不详细介绍了。 因为它所做的只是优化,所以为了简单起见,你可以省略它。 | |||
=== | === 后端 === | ||
* 首先,'''code generator 代码生成器'''(译者注:这里Code指可执行代码) 读取中间表示,并生成出类似汇编的代码,唯一的区别是,为简单起见,它假定目标是一台具有无限数量的寄存器 (或其他资源) 的机器。 | |||
* 其次,'''register allocator寄存器分配器''' 通过决定何时将变量存储在寄存器或内存中来处理CPU上的可用寄存器。 这部分对性能会有 ''主要'' 影响。 一旦完成,类似汇编的代码就会变成真实 '''汇编'''。 | |||
* 然后,'''assembler 汇编器''' 读取汇编并输出 '''machine code 机器码'''。 通常,代码仍然有一些未解决的引用问题(译者注:指对外部库的依赖引用),因此将机器代码放入 '''object file 目标文件 ''' 中。 | |||
* 接下来,'''链接器(linker)''' 通过将目标文件与库链接并替换指向库内正在引用的资源的指针来满足目标文件中每个未解析的引用。 链接器还提供必要的信息,以便在动态链接时定位相关库,或者在静态链接时,特定库的一些或全部可能嵌入到目标文件中。 链接器有时被认为是与后端甚至编译器分开的,但事实是,特定链接器的操作特定于它链接的目标 (或目标族),所以我将其包括在编译器后端类别中。 | |||
* 最后,后端将解析所有引用,通过添加目标程序加载机制所必需的元数据,将目标文件转换为可执行文件,以达到能识别程序,加载它,在必要时动态链接它并运行它。 | |||
后面很快,我将讨论如何实际编写这些内容。(译者注:然而并没有:-p) | |||
2022年3月19日 (六) 03:37的最新版本
|
|

所以你想从头开始制作自己的 编译器?
这并不容易。 有些编译器的复杂度与整个简单操作系统相当。
尽管如此,它还是一个有趣且/或有教育意义的项目。 以下是开始之前你应该知道的一些事情:
利弊
为什么要编写编译器而不是使用现有的编译器?
优点:
- 你想要的语言和目标的编译器可能根本不存在。
- 教育目的,你可以更好地了解 内核、编译器和运行时库如何一起工作,以及实现一种语言需要什么。
- 说到这里,你可以立即实现自己的新编程语言!有多酷啊?
- 你可以对正在编译的程序执行几乎任何操作:
- 以你喜欢的格式添加调试数据
- 添加分析辅助工具
- 重新编写和重新排列程序的各个部分
- 针对特定事物进行优化
- 将其扔掉并替换为其他程序
- 编译的程序将针对你的机器或你正在开发的操作系统定制。
缺点:
- 需要完全理解所需的语言。要始终制定充分的官方语言规范。
- 还需要了解特定于目标的汇编过程。
- 关于 起步指南这篇文章的大多数注解也适用于编译器。
- 完全实现一套语言规范将很棘手。
- 如果你想在编译代码的大小/速度优化方面与GCC竞争,则必须非常非常擅长做编译器。
术语
好吧,如果你还打算要做,现在让我们看看编译器是如何工作的:

术语:
- “Host主机” 是编译器本身运行的环境。
- “Target目标” 是要运行编译后得到程序的地方。
- “run-time运行时” 是目标上存在的资源 (库,进程等)集合。 两台具有相同硬件的机器在运行时资源的可用性方面不同,有时则被认为是不同的目标,因此一个程序可能在一个计算机上运行,但不能在另一个计算机上运行。
- “可执行文件-executable” 是一种文件,其中包含目标启动程序所需的信息。 它通常是直接的二进制文件,但通常结构更精细,例如包含链接和重新定位信息。
- “link链接” 表示程序知道如何与运行时对接,并依赖运行时的某些功能。 它是由 链接器 创建的,并且在自主(free-standing)程序 (即OS内核) 中不存在。
如果主机和目标是相同的,则产品是 “原生可执行文件(native executable)”。 99%的情况下,你遇到的就是这种。 如果编译器能够为与主机不同的目标生成可执行文件,则它就属于 “交叉编译器(cross-compiler)”。 如果编译器能够编译出自己,那就是 “自我托管(self-hosting)”的。
内部

编译器也有奇特的内部结构。 你不必完全能复述这里描述的那些定义,但目前这是一个很好的路线图。 通常,编译程序的任务分为几个单独的任务:
- Front End 前端 采用某些特定语言的源代码,并输出通用的 “中间表示” (IR)。
- Middle End 中端 (可选) 采用中间表示形式,以某种方式对其进行更改,然后将其输出回去。
- Back End 后端 获取IR并输出特定目标的可执行文件。
这种划分的想法是,通过具有不同前端和不同后端的集合,你可以将任何语言的程序编译到任何目标,因为IR对于所有目标都是相同的。
前端
- 首先,前端通常包括某种用户接口,以便可以接受文件和编译选项。 然后,有几个阶段的处理。
- 对于类似C的语言,会有一个 pre-processor 预处理器 从头文件中复制并粘贴代码,删除注释执行宏扩展并执行其他相对简单的任务。
- 然后,一个 scanner 扫描器 (或 tokenizer 分词器) 将源文件分解为一系列分词(Token),代表一种语言的基本单词 (即标识符,数字和字符串常量,诸如 “if” 和 “when” 的关键字,标点符号和分号)
- 然后,parser解析器 读取令牌流并构造 parse tree解析树,这是一种树状结构,表示源代码的结构。 就语言制作而言,每个源代码文件都是该语言的 “sentence 句子”,并且每个句子 (如果有效) 都遵循特定的语法。
- 接下来,semantic analyzer 语义分析器 遍历解析树,并确定该 “句子” 每个部分的特定含义。 例如,如果是声明语句,则它将条目添加到符号表中,并且如果它是涉及变量的表达式,则它将符号表中已知变量的地址替换为表达式中的变量。
- 最后,前端生成一个 Intermediate Representation 中间层表达,它捕获程序源代码特定的所有信息。 一个好的IR可以说明源代码所表达的所有内容甚至更多,还可以捕获该语言对程序的其他要求。 它可以是 parse tree 解析树 、 abstract syntax tree 抽象语法树 、 three address code 三地址代码 或更奇特的东西。
值得注意的是,这种划分纯粹是为了方便编译器开发人员。 大多数类型的 parsers 解析器 可以轻松读取字符流,而不是分词令牌流,因此不需要单独的扫描器。 一些非常强大的解析器类甚至可以 “在阅读完成之前” 确定语句的语义含义,因此不需要语义分析器。 不过,它们可能会更难理解和使用。
中端
这里会使用一大堆旨在尝试使程序更高效的算法。 我对这部分不是很熟悉,所以我就不详细介绍了。 因为它所做的只是优化,所以为了简单起见,你可以省略它。
后端
- 首先,code generator 代码生成器(译者注:这里Code指可执行代码) 读取中间表示,并生成出类似汇编的代码,唯一的区别是,为简单起见,它假定目标是一台具有无限数量的寄存器 (或其他资源) 的机器。
- 其次,register allocator寄存器分配器 通过决定何时将变量存储在寄存器或内存中来处理CPU上的可用寄存器。 这部分对性能会有 主要 影响。 一旦完成,类似汇编的代码就会变成真实 汇编。
- 然后,assembler 汇编器 读取汇编并输出 machine code 机器码。 通常,代码仍然有一些未解决的引用问题(译者注:指对外部库的依赖引用),因此将机器代码放入 object file 目标文件 中。
- 接下来,链接器(linker) 通过将目标文件与库链接并替换指向库内正在引用的资源的指针来满足目标文件中每个未解析的引用。 链接器还提供必要的信息,以便在动态链接时定位相关库,或者在静态链接时,特定库的一些或全部可能嵌入到目标文件中。 链接器有时被认为是与后端甚至编译器分开的,但事实是,特定链接器的操作特定于它链接的目标 (或目标族),所以我将其包括在编译器后端类别中。
- 最后,后端将解析所有引用,通过添加目标程序加载机制所必需的元数据,将目标文件转换为可执行文件,以达到能识别程序,加载它,在必要时动态链接它并运行它。
后面很快,我将讨论如何实际编写这些内容。(译者注:然而并没有:-p)